
深圳中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2021-06-18 来源:黑马程序员 浏览量:
学习Scrapy框架,从理解它的架构开始。
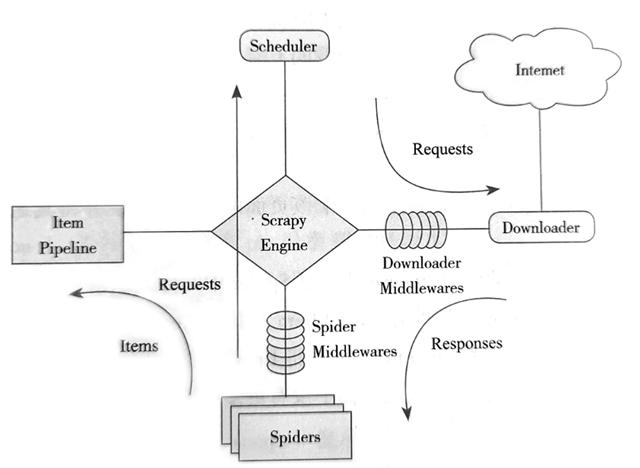
Scrapy框架
从上图可知,Scrapy框架主要包含以下组件:
(1) Scrapy Engine (引擎) :负责Spiders、Item Pipeline、Downloader、Scheduler之间的通信,包括信号和数据的传递等。
(2) Scheduler (调度器):负责接收引擎发送过来的Request请求,并按照一定的方式进行整理排列和人队,当引擎需要时,交还给引擎。
(3) Downloader (下载器) :负责下载Scrapy Engine 发送的所有Requests (请求) ;并将其获取到的Responses (响应)交还给Scrapy Engine,由Scrapy Engine交给Spider来处理。
(4) Spiders (爬虫) :负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进人Scheduler (调度器)。
(5) Item Pipeline (管道):负责处理Spiders中获取到的Item数据,并进行后期处理(详细分析、过滤、存储等)。
(6) Downloader Middlewares (下载中间件):是一个可以自定义扩展下载功能的组件。
(7) Spider Middlewares (Spider中间件):是一个可以自定义扩展Scrapy Engine和Spiders中间通信的功能组件(例如,进人Spiders的Responses和从Spiders出去的Requests)。
Scrapy的这些组件通力合作,共同完成整个爬取任务。架构图中的箭头是数据的流动方向,首先从初始URL开始,Scheduler 会将其交给Downloader进行下载,下载之后会交给Spiders进行分析。Spiders分析出来的结果有两种:一种是需要进一步爬取的链接,例如之前分析的“下一页”的链接,这些会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline,这是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
猜你喜欢:




















.jpg)